The Jedi Mind Tricks in the New Climate Science Reference Guide for Judges-Part 1: IPCC Ratings
The misrepresentation, errors, and omissions subtly persuade judges to rule in favor of plaintiffs in climate-related suits


The 1993 Supreme Court Decision in Daubert v Merrell Dow Pharmaceuticals, Inc emphasized the gatekeeping role of judges as screeners of scientific evidence and expert scientific testimony for admissibility into evidence in trials. The Daubert test that arose from the case suggests several factors that judges may look at to decide admissibility of scientific evidence: whether it’s published and peer-reviewed, generally accepted by the scientific community, tested, controlled by standards, and capable of having its error rates measured.
To assist judges in assessing the credibility of scientific evidence following Daubert, the “Reference Manual on Scientific Evidence” has been published by the Federal Judicial Center (FJC) since 1994. The third edition and the new fourth editions (2025) have been co-published by the FCJ and the National Academies of Sciences, Engineering, and Medicine (NASEM). The NASEM Commitee On Science For Judges-Development of the Reference Manual on Scientific Evidence, Fourth Edition selected the chapters to be included, recruited authors to revise or add new chapters as needed, approved the chapters, and managed the review process.
The reference manual features expert-authored guides that cover the basic principles of various scientific disciplines, such as epidemiology, human DNA identification, and statistics. These guides serve as a resource for judges who are considering the admissibility of expert testimony. The reference guides also offers helpful background on scientific disputes that may arise between experts. The fourth edition of the reference manual added new reference guides on Artificial Intelligence, Computer Science, and Climate Science to meet the needs of judges who are seeing more cases in these areas.
The new computer science guide is unobjectionable. It essentially gives judges a crash course in the basics of computing. The reference guide on Artificial Intelligence seems even-handed, but omits much necessary material on generative AI that will be necessary for judges to understand. I’ll analyze the AI guide in a future note.
However, the climate science reference guide stands out from the other guides. Co-authored by climate legal expert Jessica Wentz and climate scientist Radley Horton, both of Columbia University, the climate guide lacks the balance and objectivity of the other guides. It misrepresents the meaning of Intergovernmental Panel on Climate Change (IPCC) ratings on climate change issues, making them seem much more relevant for judicial decisions than they really are. The climate reference guide explains to judges how they should interpret the statistical evidence they are very likely to see in climate-related suits, but the explanations are well-known statistical fallacies that make statistical evidence appear to be much stronger than it really is. The guide misrepresents the debate between climate attribution scientists on the applicability of their sub-field to legal cases, supporting the side of the debate that would make it much easier for climate plaintiffs to prove causation. It emphasizes authority as the most important source of scientific information while omitting any discussion of the most important independent check on authority—whether the research has been replicated and tested. Finally, the climate reference guide omits discussion of models and methodologies judges are likely to see in real cases, making climate expert testimony questions seem more straightforward than they really are.
These misrepresentations, errors, and omissions are buried in a mountain of mostly irrelevant boilerplate climate material essentially lifted from Intergovernmental Panel on Climate Change (IPCC) publications. A judge, overwhelmed by all the detail, could easily glide over the subtle advocacy in the reference guide, coming away with the impression that technical issues in climate cases are much more clear than they really are.
Because there is a lot to cover, I’ll analyze the misrepresentations, errors, and omissions in the climate reference guide in a series of notes.
Part 1: Misrepresentation of the meaning of IPCC ratings
Part 2: Statistical fallacies in the climate reference guide for judges
Part 3: The debate between climate attribution scientists misrepresented
Part 4: Reliance on academic prestige and authority rather than independent verification
Part 5: How the climate reference guide should be re-written
Misrepresentation of the Meaning of IPCC Ratings
The reference guide begins by going over basic principles of climate science. This discussion is similar to the other guides, which present the foundations of the scientific disciplines they cover. This is all boilerplate background that is not especially pertinent for judicial decision-making. But then, in the section “Communicating Uncertainty,” the climate guide gets into an issue that is very important for judicial decisions: communication and management of scientific uncertainty. The climate guide asserts that climate scientists use what it calls “standard” techniques for communicating uncertainty and then offers as an example of these standard techniques the rating system the IPCC uses in its publications.
The guide claims that it is a “standard” technique to communicate uncertainty as the IPCC does by using a rating system to communicate 1) confidence in scientific findings, 2) the level of agreement, 3) the availability of evidence, and 4) the likelihood of an event or outcome. In the IPCC rating system, scientists’ level of confidence about a finding might be rated as “high” or merely “medium.” Similarly, IPCC authors might judge an outcome to be “very likely” or “likely.” Such a rating system would be welcome news to judges concerned with the question in the Daubert test of whether the scientific evidence is capable of having its error rate estimated.

But if this rating system is really a standard technique, why do judges not find any equivalent ratings system in any other guides in the reference manual? A guide may discuss governmental and non-governmental reports appropriately, as was done in “Reference Guide on Forensic Feature Comparison Evidence,” because those reports may be cited as evidence. But no other guide has a list from an official organization equivalent to the IPCC with findings labeled “very likely” or the degree of confidence pronounced “medium.”
Why is that? The reason is that the IPCC exists for a specific purpose—to support policymakers. Climate science has enormous policy implications. The IPCC was created by government policy makers and given the difficult task of summarizing a large mass of highly complex and technical climate research for non-technical policy makers to use as one of many inputs into the climate policy process. Because the climate literature is vast, but policy makers need to understand the bottom line on findings simply, the IPCC also created the rating system.
However, the benefits of summarizing technical issues in non-technical language and of providing policy-makers with a common yardstick—a rating system—do not come without significant costs and caveats. Anyone who has ever read a popularization of any technical subject, thought he understood it, and then went on to study it technically, will immediately realize how shallow and misguided his former understanding was. The IPCC in general does a very good job of summarizing technical climate research. But any popularization or summary, no matter how carefully done, is bound to omit important details, subtleties, and qualifications.
The IPCC rating system has similar problems. No body of scientific evidence can really be fairly described by a simple rating system, which is the reason other scientific disciplines do not employ one. Because an accurate rating system cannot be imposed by any central scientific authority, the IPCC takes a practical approach to implementing the rating system by allowing authors of individual chapters in IPCC documents to interpret their particular evidence as they see fit, as long as they observe the general guidelines. For example, in the IPCC Guidance , authors are told that in assessing likelihood of an outcome of event, they may use statistical evidence, modeling, other quantitative techniques, or expert judgment. According to IPCC guidance, authors should map their evidence into a table of probabilities. A “likely” rating should have a probability of between 66%-100%. A likely climate finding could therefore satisfy a preponderance of the evidence standard if used in a courtroom, although the IPCC never developed the ratings for that purpose
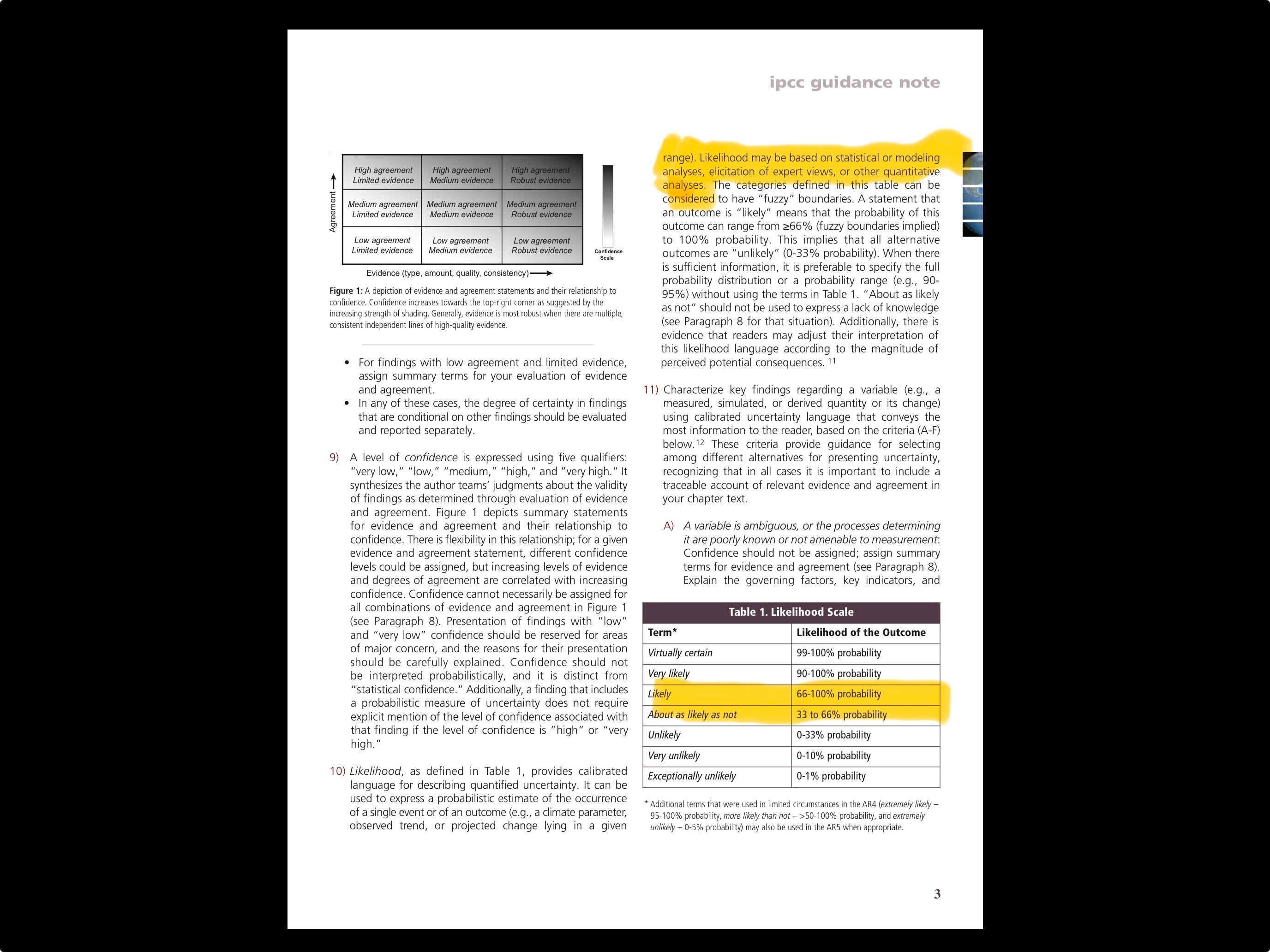
.
Climate policy makers must live with the tradeoff between accuracy and accessibility of climate research. This tradeoff is even more problematic when IPCC ratings are transposed outside of their intended policy-making sphere into other areas, such as the courtroom. Climate policy makers are already experts in the subject areas they cover and are thus less likely to misinterpret IPCC ratings. Judges are not climate experts though. While IPCC ratings help policy makers categorize a mountain of climate evidence, they also may mask important details that may not matter so much for policy work but which could be vitally important in a courtroom.
Examples of how IPCC ratings can be misleading in a courtroom
Since the IPCC ratings process is subjective, it is difficult to get transparency into how ratings are assigned by IPCC document authors who are summarizing climate research. Occasionally, authors of academic climate papers, anticipating that their research may be used by IPCC author teams, will rate findings themselves in accordance with IPCC standards so that the IPCC authors will be able to consider the researchers’ own views when summarizing it. The climate reference guide cites two papers that happen to do that. They can serve as case studies since both papers are highly relevant for climate cases and they are transparent about how they assigned their ratings.
Increased precipitation from climate change
The climate reference guide cites as an example of a “likely” rating a paper entitled Attributable Human-Induced Changes in the Likelihood and Magnitude of the Observed Extreme Precipitation during Hurricane Harvey, published in Geophysical Research letters. This paper studies whether the precipitation during intense storms such as Harvey, which causes flooding damage, is made worse by climate change. The paper’s findings could be highly relevant in cases in which plaintiffs are suing defendants for damages created by climate-related increased precipitation. For example, in CLF v Shell Oil Products et al, the Conservation Law Foundation sued Shell oil under its Clean Water Act obligations, alleging that Shell did not adequately prepare its Providence Island fuel terminal for foreseeable increased flooding and precipitation resulting from climate change. Since this academic paper finds that it is “likely” that climate change increased the chances of precipitation from Hurricane Harvey in Houston, isn’t that prima facie evidence that Shell should have known that increased precipitation is forseeable and therefore should have taken additional preventive measures to protect the water supply under its Clean Water obligations?
A judge, misled by the chapter’s assertion that expert ratings systems are standard practice in scientific disciplines, might be tempted to conclude climate-induced increased precipitation is entirely forseeable. But if we dip into the paper’s technical content, we’d likely reverse that conclusion.
The paper employs a statistical analysis called extreme value theory to study unusually large precipitation events around Houston. Extreme value theory is widely used to model random rare extreme events such as weather events, stock market crashes, and operational risk events in insurance and finance. I’ve used extreme value theory myself on occasion to model operational risk events in banks.
Extreme value theory is very useful in modeling the probability that the event under consideration will exceed some predefined value. In this case, the authors, using rain fall data from 1950 to 2017, are estimating the probability that rainfall around Houston will exceed some particular level. They estimate that probability under a counterfactual world in which there is no climate change and under the actual world of climate change. Then they take the ratio of the probability of extreme rainfall under climate change to the probability of extreme rainfall under no climate change. If that ratio is greater than one, then they would claim to have found evidence that climate change has increased the probability of extreme rainfall.
How do the authors get to the conclusion that it is likely that climate change increases extreme precipitation? By lowering the usual standards for statistical significance, which they are allowed to do under IPCC rating guidance. Normally in statistical studies we are concerned with estimating parameters and judging whether they are statistically significant. The standard level of significance is the 5% level while confidence intervals are calculated at 95%. Tests of statistical significance are also conducted at more stringent levels, such as 1% for significance and 99% for confidence intervals. These are common significance standards observed in statistical studies across disciplines, whether medicine, economics, or engineering.
In the extreme rainfall paper, however, the authors relax the statistical significance standards and calculate a confidence interval from 66%-100%. As they explain, they perform this calculation because it coincides with the IPCC’s “likely” standard. They calculate this confidence interval for the ratio of the rainfall exceedance probabilities and show that a ratio greater than one is at the bottom of the 66% confidence interval. That’s their basis for reporting that it is likely that climate change increased the probability of extreme rainfall.

The authors are very careful not to misinterpret what their likely finding means. The common misinterpretation would be that the authors have estimated that the probability is greater than 66% that the ratio of the probabilities is greater than one. The authors do not claim that. It is a common statistical fallacy to misinterpret confidence intervals to be making legitimate statements about likelihood.
Instead, the authors claim that their statement means they have established “granger causality” between climate change and extreme rainfall. Granger causality is a statistical concept. Roughly speaking, X granger causes Y if X can predict Y. Importantly, however, granger causality doesn’t establish actual causality as the authors indeed confirm: they did not establish actual causality between climate change and extreme rainfall, an important fact in a legal setting.

It’s also vital to note that they did not establish Granger causality at conventional statistical significance levels, such as 5% or 1%, either. As they admit, they use a much lower standard of statistical significance than would be acceptable in other scientific disciplines. The lower standard of statistical significance is arguably acceptable if used in a policy setting, although there may well be controversy between policy makers about that.
The IPCC rating standards give authors great leeway to define the ratings as long as they conform with the general guidance. But from a legal standpoint, the likely rating hides two essential facts that are highly relevant in a courtroom: 1) the authors acknowledge they did not find causation between climate change and extreme precipitation; and 2) to establish the weaker granger causation they used statistical evidence that is much weaker than employed in other fields. Outside of a policy setting, significance at a 66% confidence level would be dismissed as a finding of no statistical evidence.
Stronger hurricanes from climate change
The climate reference guide also notes that the IPCC has given a “likely” rating to the proposition that climate change has already caused the global proportion of intense tropical storms (TC)-category 3-5 hurricanes-to increase over the past four decades. This finding would be key in any climate lawsuit alleging damages from a recent hurricane. Cases have already started to appear. For example, in Municipalities of Puerto Rico v Exxon et al, Puerto Rican cities sought to hold Exxon and other oil companies responsible for their alleged role in making Hurricane Maria worse through climate change. That case was recently dismissed on procedural grounds-not on the merits-but there will doubtless be others to come. The plaintiffs’ complaint assumes that it is already an established fact that hurricanes have been made worse by climate change and that oil companies knew this fact and concealed it. The plaintiffs accuse the oil companies of violation of RICO, of fraud, etc.
But can plaintiffs assume that it is a scientific fact that hurricanes have already been made worse by climate change? Suppose the case had proceeded and the defense wanted to have an expert testify that the scientific case had not been made and therefore the defendant couldn’t have foreseen it. Should the judge allow this testimony? If he had consulted the climate reference guide, he would have seen that the IPCC has said that it is “likely” that climate change has increased the global proportion of intense tropical storms like Maria. The judge in this case might well decide that the defense’s expert is challenging a consensus scientific view and disallow the testimony.
The question then is whether the “likely” rating really represents a consensus scientific finding that is relevant in a court room rather than a policy environment. To find out we’ll need to follow the trail from the IPCC rating to the underlying evidence.
If we consult chapter 11 of the IPCC AR6 report, we can see the source of the “likely” rating is the 2020 paper Global increase in major tropical cyclone exceedance probability over the past four decades by Kosin et al. Dipping in to that paper, we see the conclusions are much more nuanced than the “liklely” rating would suggest. The authors note that they have not performed a formal detection (based on climate modeling) of the trends in hurricane intensity.

Instead, they justify their view that it’s likely that hurricanes have intensified as a result of climate change on storyline, balance of evidence, and Type II error grounds. They don’t explain what they mean by that in this paper but rather cite further papers. We’ll need to go to those papers next.
If we follow the academic paper trail of cites, we arrive next at the critical paper Tropical Cyclones and Climate Change Assessment: Part I: Detection and Attribution. This paper surveys hurricane experts. Recall that IPCC rating guidance gives considerable latitude to define what the ratings mean. Expert judgment is explicitly allowed.
Examining the paper, we find that it offers two expert assessments, aimed at two audiences, a scientific audience and a climate policy-maker audience. The scientific audience assessment uses a Type I error standard, a standard in which you are more concerned about the mistake of confirming an effect—such as increased intensity of hurricanes from climate change—when the effect is not really there. Traditionally, scientific judgments require the high standard of proof delivered by a Type I error standard. The climate policy audience assessment is made under a Type II error standard, a standard in which you are more worried about the mistake of not confirming an effect even although it’s really there. A Type II error standard is appropriate when you are focused on risk management rather than scientific proof. From a risk management point of view, a policy maker wants to know if there is a sufficiently high risk that hurricanes have already gotten stronger as a result of climate change. Policies could then be adjusted to manage the risk. Type II is the “better safe than sorry” evidence standard.
Under the Type I standard, the majority of experts had low confidence that human-induced climate change have influenced hurricanes so far. Under the Type II standard, a majority of the experts surveyed agreed that climate change has already made increased the proportion of extreme hurricanes, although the paper acknowledged a substantial chance that this view is mistaken.

Clearly, then the IPCC “likely” rating can’t be taken at face value in a courtroom. From a scientific point of view, the Kossin et al paper acknowledged that it didn’t have the traditional observational and model-based proof that hurricanes have already been made worse by climate change. From an expert judgment scientific point of view, the experts in the detection and attribution paper couldn’t agree that climate change has already made hurricanes worse. It’s only when they shift to a policy point of view that a majority of the experts can label it “likely.”
The detection and attribution paper the IPCC ultimately relies on reports two results because it has two audiences, scientists working in the field and policy makers who read IPCC reports. The IPCC, since it is set up to serve policy makers, reports the policy point of view, not the scientific point of view. But courts are looking for the scientific point of view. The IPCC “likely”rating, when transposed into a courtroom setting it wasn’t designed for, obscures all the necessary nuance.
This obfuscation is a general problem with any rating system that tries to communicate complex scientific results simply. No other guide in the judicial reference manual refers to any scientific rating system, and for good reason. Ratings can’t testify nor can they be cross-examined. A climate reference guide that seeks to explain the facts of climate science to judges should not refer to IPCC ratings as a potential source of truth to decide expert testimony questions. Ratings are too easy to misinterpret in the legal setting they were not designed for.