The Jedi Mind Tricks in the New Climate Reference Guide for Judges
Part 4: Peer-reviewed published research on climate economics might be badly wrong


Note: this post is a bit wonkish but you’ll see some academic chicanery in the wild if you persist
As we’ve seen in previous parts of this series, the climate reference guide for judges puts most of its emphasis on the use of IPCC and other official reports as definitive arbiters of the climate science questions that may arise before a court. The reference guide strongly recommends using consensus reports from the IPCC and other official bodies; judges should resort to individual studies only when they are necessary supplements. Thus, there is little guidance given about how to review and use single papers.
However, the reference guide is stuck in the mentality of 2015, when the IPCC reviews were seen as preeminent. In the last 10 years, the academic climate literature, particularly as it applies to potential court cases, has moved on from IPCC reports. Judges will very likely be faced with adjudicating climate science questions that are based on an individual study or a set of related studies. In part 5, I’ll discuss more completely the models and methodologies that were left out of the reference guide but are nonetheless relevant. In this note, I’ll focus on one of the most important strands of the new academic climate literature, the application of economics and econometrics (statistics applied to economics) to climate questions.
Of course, economics and econometrics don’t have the same certainty as the physical sciences. The climate reference guide glides over the differences between results that depend on the physical sciences and results that depend on economics, describing the conclusions from analyses that rely crucially on economics as “fairly robust.” However, economists are well-known for forming a consensus on an issue and then making predictions that turn out to be dead wrong. Methodologies that crucially rely on economics must face a heightened standard of scrutiny in the courtroom.
Even if the academic papers that explain the climate economic and econometric methodologies are published in prestigious peer-reviewed academic journals, and even if the authors have unimpeachable academic pedigrees, there is no guarantee that they don’t have serious weaknesses that have not been acknowledged or corrected. The academic referee process is essentially a challenge process, not a model validation process. Academic peer review, especially when conducted on papers that rely on econometrics, can fail to uncover serious weaknesses and problems. And if these problems are discovered after publication, they are not always rectified.
We often think of scientists as objective and disinterested, but there are all kinds of perverse incentives in the academic publishing process that determines compensation and careers. Sometimes when academic papers are known to have severe weaknesses or are even incorrect, authors and journals are loath to correct them after they’ve been published.
I’ll illustrate these problems by discussing two econometrically-based climate papers, both of which had a large academic and practical influence before serious flaws were discovered. In both cases, the authors, the authors’ academic institutions, and the journals that published them resisted correcting the record. I’m not suggesting that these case studies imply these problems are automatically present in the climate economics and econometrics literature. Rather, I’m presenting these case studies as cautionary tales on what can and does go wrong. In the end, I’ll offer some advice on how to protect against blatantly false published research being introduced into evidence.
Case Study 1: The Sustainability Paper
In 2014, The Impact of Corporate Sustainability on Organizational Processes and Performance was published in Management Science. The authors had serious academic pedigrees: two were from the Harvard Business School (HBS) and the other author was from the London Business School (LBS). Management Science is a prestigious peer-reviewed academic journal. The paper claimed to show that companies that were early adopters of sustainability policies had better stock return performance, a startling claim if true: companies that adopted sustainability policies could improve their financial results. The paper received huge academic and media attention and was cited over six thousand times. Government officials and former VP Al Gore touted it.
Professor Andrew King’s attemped replication
Andrew King holds the Questrom Chair at Boston University and is an expert in sustainability. He set out to replicate the paper, presumably as a starting point for his own research. However, he ran into great difficulties and soon realized the results in the paper were wrong. He detailed his experiences on LinkedIn in How Insitutional Failures Undermine Trust in Science. King was forced to publish on LinkedIn since, as you’ll see in a moment, the paper’s authors, Management Science, and the authors’ business schools refused to do anything about King’s findings.

King started out by trying to replicate the results. He soon realized that he was not getting the same results the authors did; worse, he was unsure how they could have obtained the results they did. So he did the obvious thing. He emailed the authors seeking clarification. And they ignored him.

Many academic journals do not require authors to post a replication package. Without one, it can be difficult or impossible to independently replicate the papers without the cooperation of the authors. And if the authors refuse to engage with replicators, the papers can’t be replicated.
That was the situation that King faced. He decided to turn to his academic colleagues to see if they could intervene to induce the authors to cooperate. But King was stymied by the realities of academic publishing. Academics specialize in narrow areas in which just a small number of other academics are also expert. Thus, academics rely on a small group to peer review their own papers. There is an illusion of independent, objective, peer review but in reality they all know each other. There is no benefit to exposing papers that might be wrong or embarrassing the authors or journals when your academic career depends on them. There could be retaliation if you do. So, academics sometimes don’t want to get involved. That’s what King observed.

King then decided to go directly to the journal to submit a comment. They rejected it because they didn’t like its “tone.” Presumably, however, the journal must have communicated with the authors about one of King’s findings: that a key parameter had been reported to be statistically significant when it in fact wasn’t. But they claimed it was a “typo” and didn’t correct the key finding. King asked the editors of Management Science to correct the record. They said no.

King then realized there was an even bigger problem with the paper. The method the authors claimed to have employed couldn’t have actually been used. He decided at that point to complain to HBS and LBS. HBS told King that however they chose to deal with situation, if they did deal with it, they would not inform him. LBS told King that the false claim in the paper was unintentional on the part of their author, since he didn’t do the empirical analysis.

King then decided to go outside of academia, which had closed ranks, and publish his story on LinkedIn. Just a few days after he went to LinkedIn, King heard that Management Science was going to post a correction. Management Science brazenly claimed that the authors had made the correction before King published his criticisms on LinkedIn but the journal had misplaced it, denying King any credit for having discovered and publicized it. The paper has not been retracted to this day. It likely continues to influence corporate governance policies.
Case Study 2: My Validation of the Nature Economic Damage Paper
I had a remarkably similar experience to King’s when I replicated and then found serious problems with the paper The Economic Commitment of Climate Change. Written by three prominent climate scientists from the prestigious Potsdam Institute For Climate Impact Research, the paper was published by Nature in 2024, considered perhaps the best academic journal for these sorts of analyses. The paper used econometric methods to estimate an economic damage function that allegedly showed that climate change already had caused large economic losses to the global economy and that the economic losses would continue to grow.
The paper was widely covered in the media. It was the second most cited climate paper in 2024. It was referenced by governments, the Congressional Budget Office, and read into the Congressional Record. The paper was already being used for policy purposes in 2025. In late November 2024, I decided to closely examine the paper and its results. Like King, I found serious problems.
Background on Economic Damage Functions
The climate reference guide devotes only a couple of sentences to the rapidly developing and highly relevant academic literature on economic damage functions, saying that “the use of fixed effects regression models…has been particularly noteworthy” but not commenting further.
These new fixed effects regression models are the essential ingredient in proposed methodologies that plaintiff’s might use to prove and quantify damages they allegedly suffered as a result of a defendant’s emissions. As such, these models are now very likely to be the subject of expert testimony in future climate-related court cases. And yet the climate reference guide provides almost no discussion of them.
The fixed effects regression models are a common means of estimating an economic damage function. An economic damage function is a relationship between a climate effect, such as a higher temperature, and the resulting loss of income at a regional or country level. For example, if the temperature were projected to go up be 1C in the state of Florida in the U.S. because of climate change, the damage function would predict the economic loss Florida would suffer on average.
The damage function is the essential ingredient of the more comprehensive methodologies that have been specifically proposed by climate science academics to establish and quantify the effects of climate change. For example, the 2025 Nature paper Carbon Majors and the Scientific Case For Climate Liability lays out a full methodology to assess responsibility for GHG emissions. It works as follows: first, the quantities of greenhouse gas emissions (GHG) attributed to specific plaintiffs, such as oil majors, are calculated. Then, the GHG emissions for each plaintiff are put through a simplified climate model, such as the FaIR model, to predict the increase in general temperature contributed by the plaintiff from his GHG emissions. The general temperature is then run through a statistical model that predicts what the temperature change would have been on a country or regional scale. Finally, the local temperature predictions are fed into an economic damage function, which then predicts the loss of income at the regional level that the plaintiff is allegedly responsible for. Thus, the damage function establishes causation and also quantifies the damages.
The authors of the 2025 Nature paper, who are climate scientists, not economists, developed it specifically for use in climate lawsuits. The GHG emission allocation and the FaIR model are based on the physical sciences. But the damage function is based on economics, macro-econometrics specifically. Macro-econometrics is the use of statistics applied to questions in macroeconomics. Economists use macro-econometrics to establish the relationship between factors such as taxes or government spending and large scale features of the economy, such as real GDP. The fixed effects regression models mentioned by the climate reference guide are one important set of statistical techniques used by macroeconomists. When applied to climate, fixed effects regression models are used to predict the effect of climate variables, such as temperature or precipitation, on real GDP or perhaps real per capita GDP. Climate econometrics is an important new sub-field in climate science that imports econometric methods from economics to be applied to climate problems.
Most of these new methodologies that courts are likely to see, such as presented in the 2025 Nature paper, have been developed by academics working in climate science. These methodologies use results from climate science that climate scientists are expert in, but then they also import macro-econometrics methods as well—climate econometrics. But the results that depend on these econometric models are hardly “robust” as we’ll see in the Nature damage function paper.
Damage Function Paper Peer Review Comments
I began the validation of the damage function paper by looking at the referee comments. Usually, the peer review process is a black box—you have no idea what actually happened in the review process of a published academic paper. In this case, however, Nature posted the peer review comments. When I read them, I could see an immediate problem.
Referee #2 kept insisting that the authors needed to justify the choices for the regression models they were using and also to check for sensitivity to the underlying assumptions. This is a perfectly reasonable comment and something that should always be done.

But the authors kept refusing to do it. It seemed clear that referee #2 was moving towards rejecting the paper. Ultimately, the editors at Nature brought in a new referee who dismissed referee #2’s quite valid concerns. We don’t know why this happened. But it does show that editors have enormous power. If they want the paper to be published, editors can easily bring in another referee that will break the tie in the direction they want.

Referee #4 disagreed with referee #2. Referee #4 is saying that he doesn’t know what the authors could have done to satisfy Referee #2’s concerns, since they were “generic.”
Really? Nothing could have been done? There’s quite a lot that the authors could have and should have done. For example, one sales pitch of this paper is that by including ten variations of temperature and precipitation variables in the fixed effects regression model, the damage model was able to tease out the allegedly complex effect of climate on real income in regions around the world. So let’s start by checking how many of those ten variables really matter.
Do All Those Variables In The Regression Really Matter?
One point of contention between referee #2 and the authors was the justification for the many variables that the authors included in their regression model. As I already mentioned, they had ten variations of temperature and precipitation variables in the regression model. The authors justified using all these variables based on previous research they did. Referee #2 quite properly wanted the authors to justify using them in the current paper.
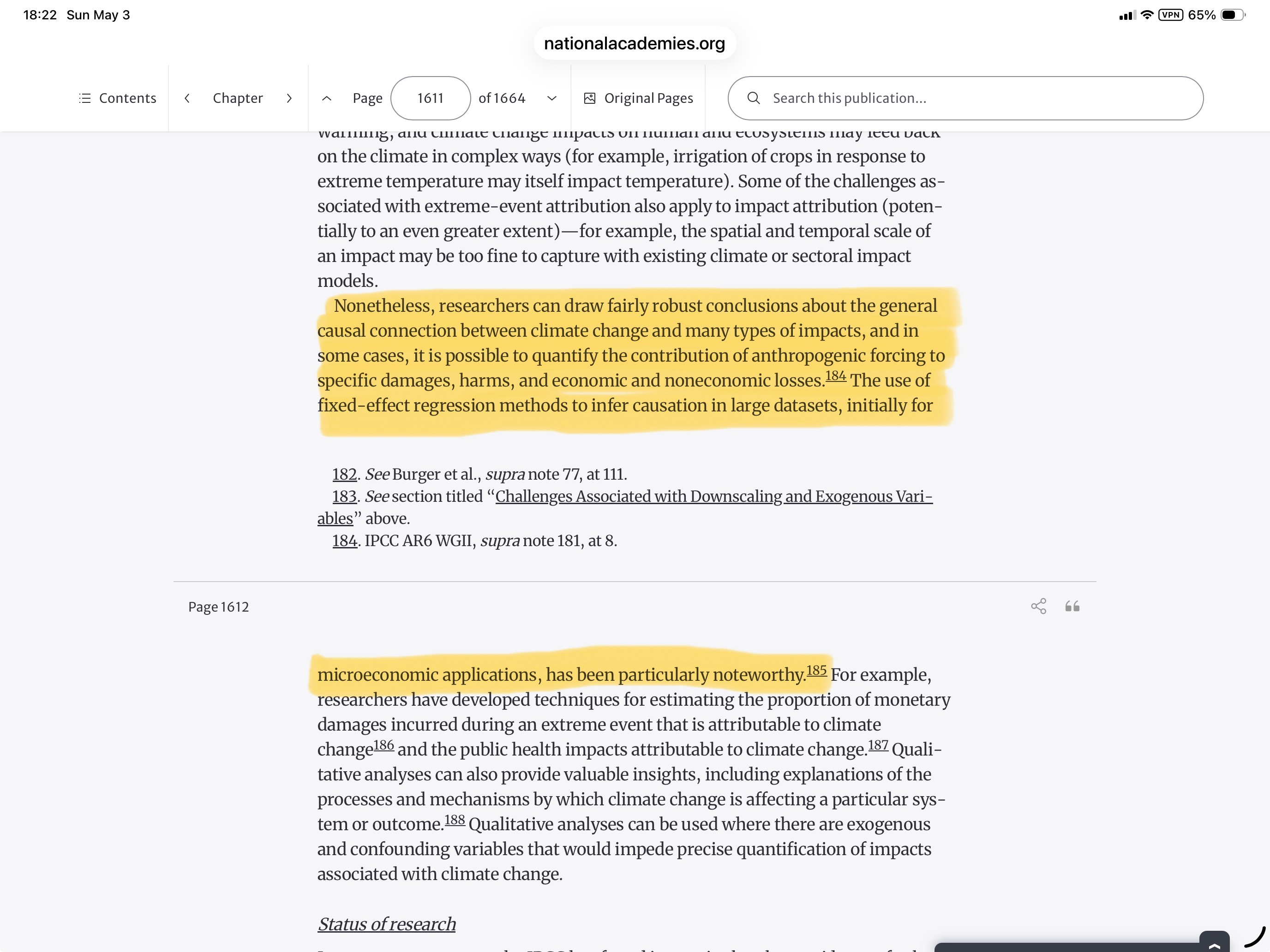
To produce their estimates of economic damage resulting from climate change, the authors simulate the model’s results using two standard climate scenarios, RCP 2.6 and RCP 8.5. RCP 2.6 and RCP 8.5 project the ten temperature and precipitation variables to 2100 under different hypothetical climate conditions. In RCP 2.6, GHG emissions get better while in RCP 8.5 they get worse. Using those scenarios, the authors calculate the median loss in global real income to 2100 under the two climate scenarios. As we see, the economic damage is in the 19% range for RCP 2.6 by 2100.
Under the more severe RCP 8.5, a climate scenario in which greenhouse gas emissions increase without any mitigation measures, loss in global real income is a whopping 60% by 2100.
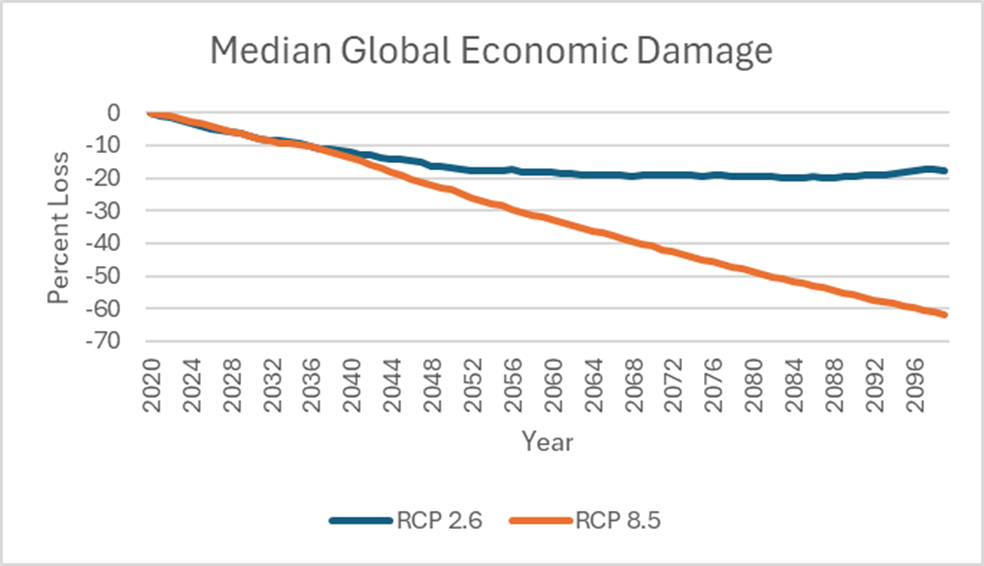
Looking at their estimates, it appeared to me that one version of the temperature variable dominated. I therefore zeroed out the coefficients of all the other temperature and precipitation variables, only keeping the one temperature variable, and re-simulated the model under the two scenarios. The chart below shows that only one variable in the model actually matters, the scaled temperature variable, producing almost all the losses.
Referee #2 was correct to request the analysis he did. If it had been done, it would have been clear that most of the variables in the economic damage model didn’t matter at all. That these variables were used in previous research was irrelevant. The major sales pitch on the contribution of this paper is illusory.
Where The Referee Comments Were Weak
Referee #2 was right to request justification for the variables the authors used in the model. But curiously, the referees seemed to let the statistical issues slide. The fixed effects regression model used in the Nature paper depended on the use of statistical tests. In general, the referees missed problems with the econometric methods the authors used, which can easily happen. An academic referee process is merely a challenge process. It’s not a replication or model validation. Academic referees don’t reestimate or resimulate the model as I’m doing.
Is the Paper’s Main Econometric Justification Valid?
Before turning to the author’s main statistical method, it will be helpful to understand why they employ it in the first place. The reason the damage model shows such large economic effects is because the model assumes that changes in temperature this year affect real GDP over the next eight, nine, or 10 years, in three variations of their model they combine. They also assume that precipitation changes this year affect real GDP over the next four years. Climate change thus has cumulative effects on real income. That’s why the economic effects in the model are so large.
But how do they justify these cumulative effects? The authors relied very heavily on the use of some technical model selection techniques, the Akaike Information Criterion (AIC) and the Bayesian Information Criterion (BIC). These statistical techniques were used by the authors to select the number of years in the model in which temperature and precipitation affected per capita real GDP in different regions around the world. The AIC and BIC criteria, according to the authors, showed that when temperature goes up today as a result of climate change, it reduces real per capita GDP for the next eight, nine, or ten years. And when precipitation gets worse as a result of climate change today, it continues to lower per capita real GDP for the next four years.
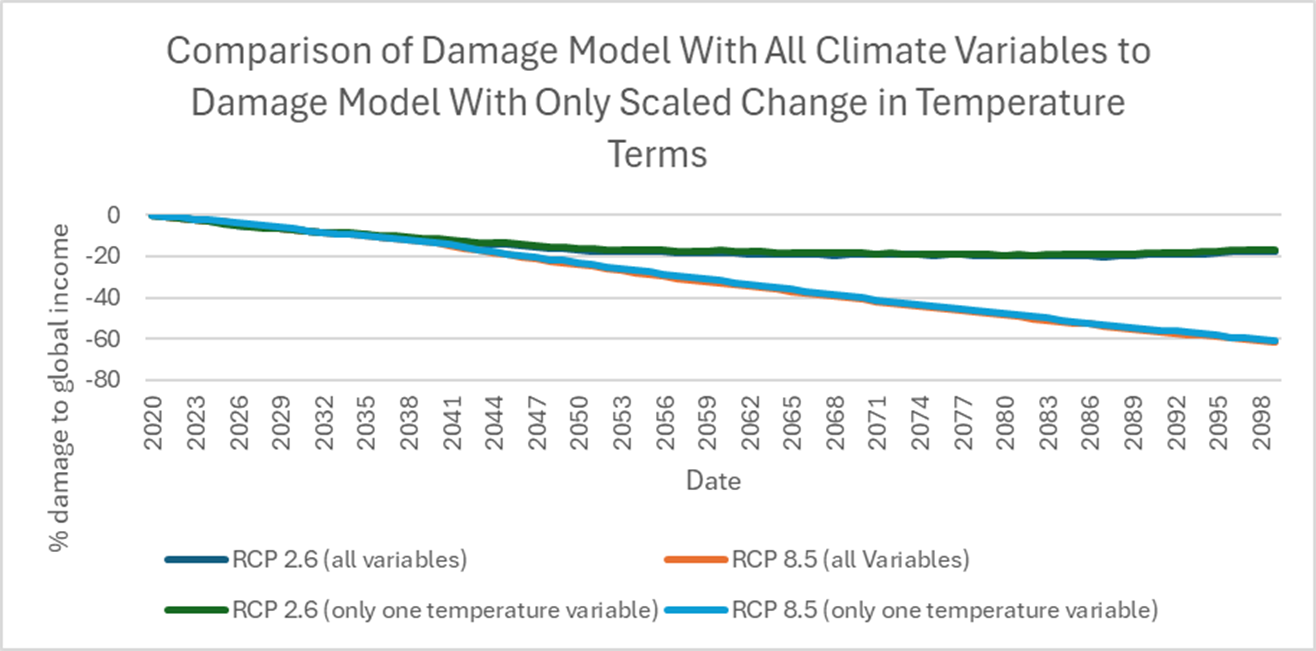
To use the AIC and BIC statistics, you are supposed to select the number of years that minimize the values of the AIC and BIC statistics. The number of years you get are called the “lags.” The authors claim that the AIC and BIC are minimized when there are either eight, nine, or ten lags of temperature variables and four lags of precipitation variables, where each lag is one year. We can see their argument on the precipitation variables in Extended Data Fig 2. that I’ve partially reproduced from their paper.
An academic referee, because he is not actually testing or validating the model, would have no way to check this claim. But since I was doing a model validation, I re-ran the regressions and the AIC and BIC tests and checked for myself. I discovered the authors made a serious mistake. When I re-estimated the paper’s regression model, I found that the AIC and BIC are smallest (i.e., most negative) when there is only one temperature and precipitation lag, not ten and four.
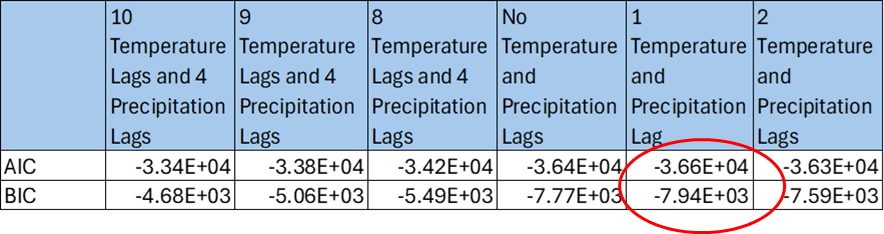
Using only one lag makes a profound difference in the model’s estimates, because the claimed large cumulative effect of climate on real income goes away. If we re-simulate the paper’s statistical model using the RCP 8.5 climate scenario with one lag of the temperature variable, economic damages get to about 10% by 2100 rather than 60% as asserted in the paper. The academic referee process did not catch this serious problem.
It Gets Worse
The authors do not spend much time focusing on the statistical significance of the climate variables they identify as producing economic damage. The referees didn’t focus on this important question either. I think the reason is that they were concentrating on the lags, because the lags produce the juice of the model. But the statistical significance of the coefficients in the model really is crucial.
In these fixed effects regression models, statistical significance is a tricky issue. The problem with these models is that they tend to show falsely that estimated coefficients are highly statistically significant, but that effect may be reversed if econometrician carefully controls for correlation. Intuitively, fixed effects macro-econometric regression models include data for a large number of regions in the world over many years, so the regression model has a lot of data. If you treat all that data as independent, the estimates will look like they are very precisely estimated and thus highly statistically significant. Correlation, however, implies that there is actually less data than it would appear, because data is in a sense repeated: it’s correlated with other data. If you don’t adjust for the correlation, you are over counting the data.
The damage paper calculates the statistical significance of the estimated parameters by assuming that the unobserved influences on real income are correlated across geographical regions. That’s a sensible assumption. The technical term for that assumption is that the standard errors are “clustered by region.” Clustering by region assumes that there are common shocks to real income that occur across regions. That assumption doesn’t overcount the data, at least along the regional dimension.
However, the paper assumes that the unobserved influences on real income are not correlated over time, an assumption that is almost certainly false. To correct the unobserved factors affecting real income being correlated across regions and over time we should “double cluster,” i.e., we should cluster the standard errors in the regression model over regions and time. Other academic papers that study the effect of climate change on economic growth double cluster their standard errors. But the damage paper authors failed to do it in this case.
The table below shows my re-estimates of the paper’s fixed effects regression model using the paper’s original assumption—clustering standard errors by region—and then comparing them to double clustering the standard errors. When you cluster standard errors, you don’t change the parameter estimates. You just change how statistically significant the estimates are.
I’ve circled in red the one temperature variable that is responsible for almost all of the economic damage. As we saw earlier, that single temperature variables produces all the economic damage in the model. As can be verified, the statistical significance of the important temperature variable (and most of the other unimportant variables as well) evaporates when we double cluster the standard errors.
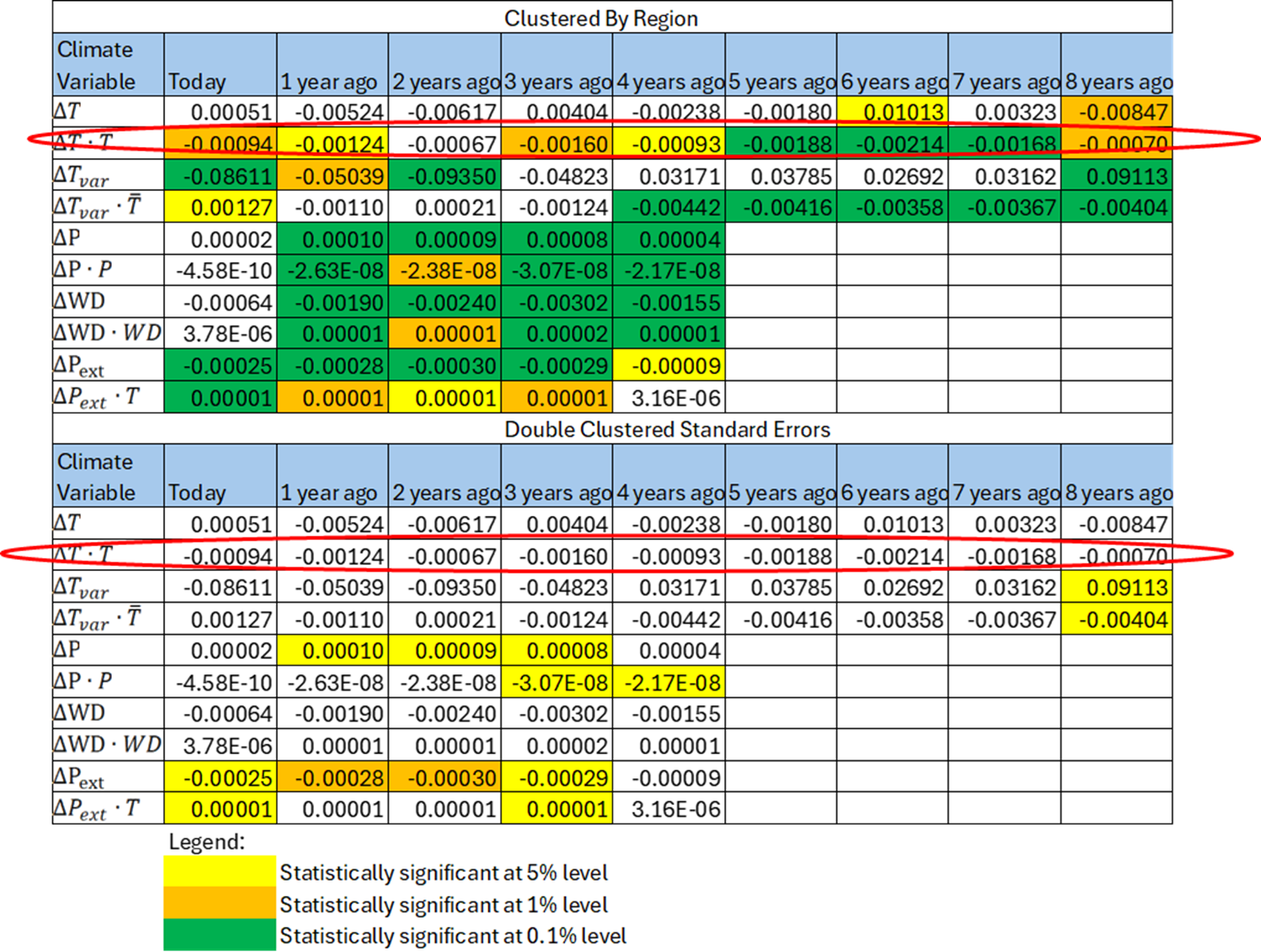
In simple terms, once we reasonably account for correlations in the model, we find that there is a statistically zero effect of climate change on real income rather than a very large one as claimed by the paper. In a peer review challenge process, an academic referee should have asked “what happens if you double cluster the standard errors as in similar climate econometric papers?” No referee raised this fatal issue. Referee #2 wanted this kind of analysis, but may not have known enough about fixed effects regression models (it’s a somewhat esoteric topic) to ask specifically for double clustering, allowing referee #4 to dismiss his concerns as “generic.” The academic referee process can fail.
Professor King Deja Vu
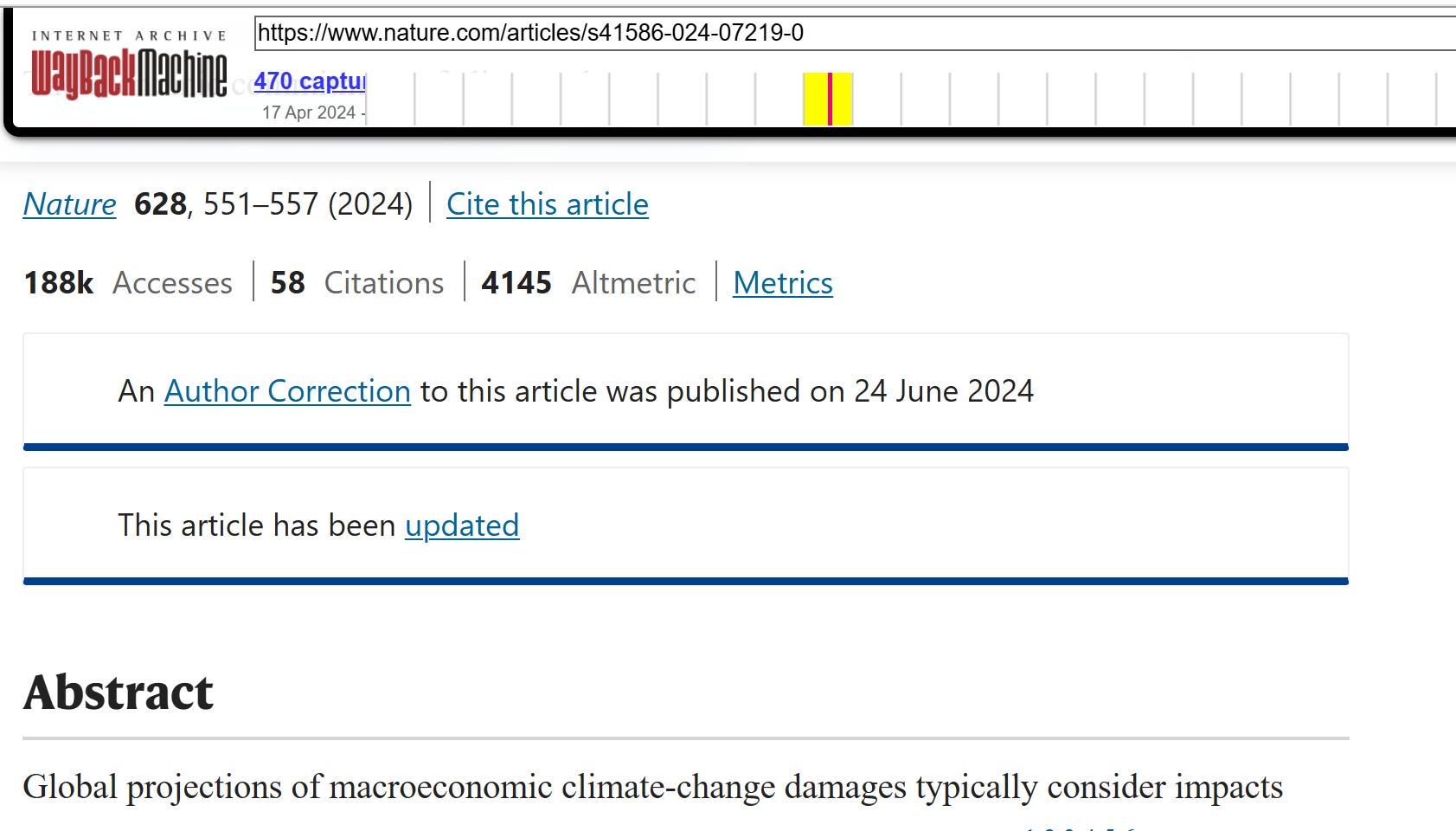
The next part of this story should remind you of Professor King’s lamentations. In early December 2024 I wrote up the results above and publicized them. I’m very sure that the authors and Nature became fully aware of the issues I raised in my early December writeup at the time I did it. In late December, I saw that Nature put up a cryptic warning on its website saying the results and data in the paper were in dispute. But they didn’t say what the issues were. Reminiscent of King’s experience with Management Science saying they misplaced the comments that they received before King posted on LinkedIn, Nature backdated the warning to November 6, which would make it appear they put up their warning before I released my results. The backdating is easy to verify using the wayback machine.
Nature warning as it appeared on 9/15/2025
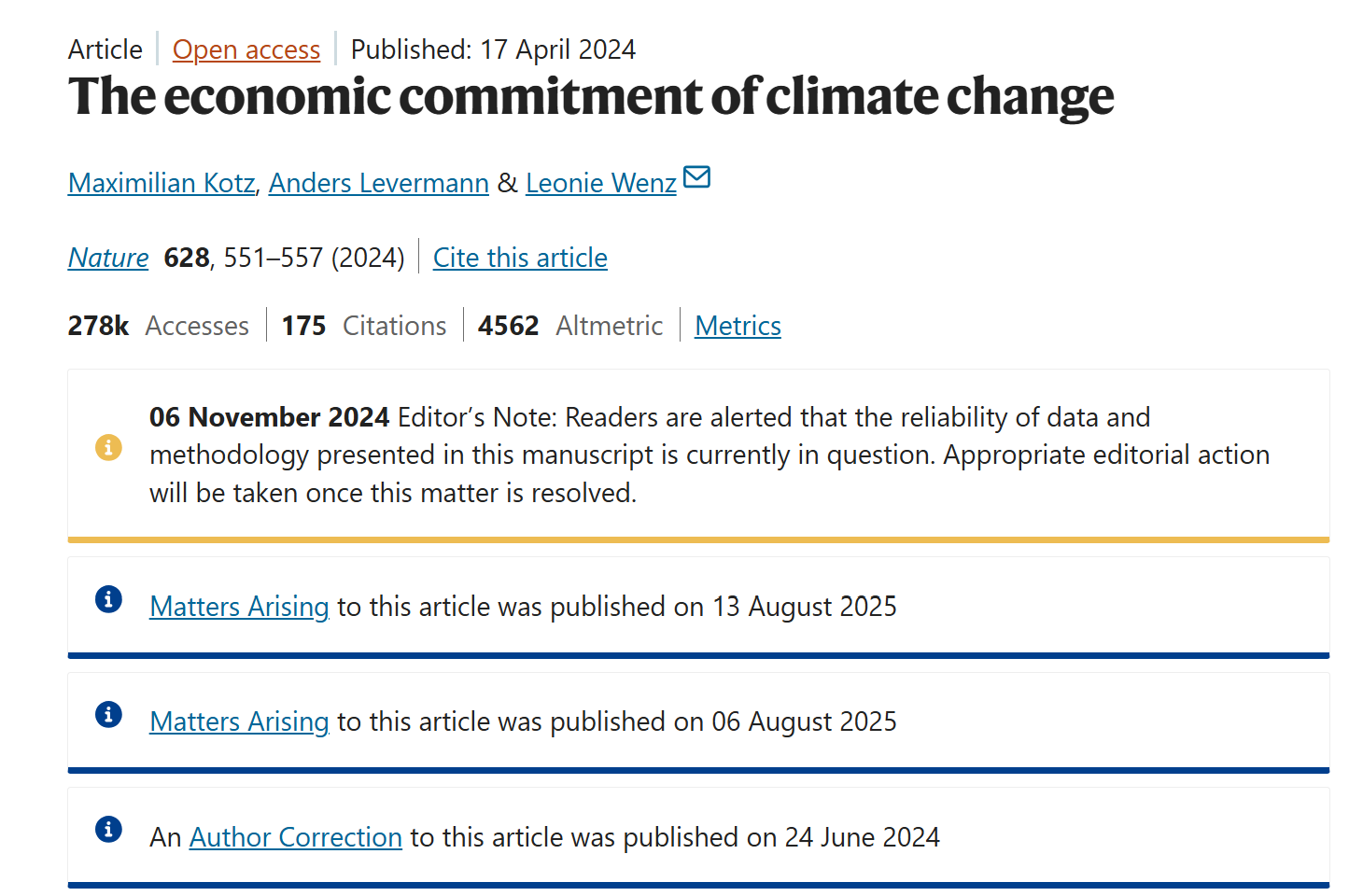
I’ll select Dec 26, 2024 From the Wayback Machine to see if the Nov 6, 2024 warning is there

Nature warning was not posted on Dec 26, 2024 but sometime after that and then backdated to Nov 6, 2024
Then Nature went silent. After a couple of months of silence, I thought I should submit a formal comment to Nature to kickstart the process. I wanted to contact them directly so that they couldn’t say later they didn’t know about my analysis, although I knew they were already quite aware of it. So, I followed their submission procedure. First, I wrote to the corresponding author of the economic damage paper, explaining my concerns and including my analysis. She didn’t respond. Then I wrote to the editors at Nature, telling them that I believed there were serious flaws in the paper, attaching my analysis, and offering to submit a formal comment. The Nature editors ignored me as well. If I had submitted a comment anyway, as King did, it may have been rejected because they didn’t like the “tone” but more likely it would have been ignored altogether. So I didn’t bother to go further.
You would think that if someone took the time to re-estimate all the regressions in the damage paper and then re-simulate the model, finding that 1) most of the variables are actually irrelevant; 2) a key statistical test was done incorrectly, invalidating the results; and 3) the coefficients of the model aren’t statistically significant, invalidating the results, the editors at Nature would have pulled the really big fire alarm in their headquarters. It’s probably quite surprising for a lot of people to learn that that’s not how the academic peer review process actually works in practice.
The Story Gets Even More Outrageous
Months of further silence went by and I eventually stopped paying attention. Then someone alerted me to a new update at the Nature website. In early August 2025, Nature posted a Paper by Solomon Hsiang, who directs the Global Policy Lab at Stanford, and some co-authors (grad students at the time at Princeton and Columbia) that showed that the damage paper contained a serious data error that had inflated the economic damage reported in the paper by almost a factor of three. Puzzled by how the economic damage could have been so big, Hsiang and his co-authors pulled the country data out one by one and re-estimated the damage model. When they pulled the tiny country of Uzbekistan out, the economic damage estimate from the model suddenly dropped very hard. A data error in the Uzbekistan data was the culprit.
Apparently errors and statistical insignificance aren’t grounds to pull the really big fire alarm at Nature, but you’d think a giant data error would cause the editors to break out the bat signal. But, surprisingly enough, that’s not how the academic peer review process actually works. Amazingly, Hsiang et al had submitted their analysis to the paper authors and Nature a year before Nature finally acknowledged it in early August 2025. So while the damage paper was being cited by government agencies and incorporated into policy, Nature and the damage paper authors were sitting on the knowledge of a giant data error and on my own results on the statistical flaws in the paper.
You can’t blame this long delay on the need for careful, methodical academic review. When I saw Hsiang et al’s paper, it took me only a short time to break out the Nature damage model and verify Uzbekistan’s anomalous effect.
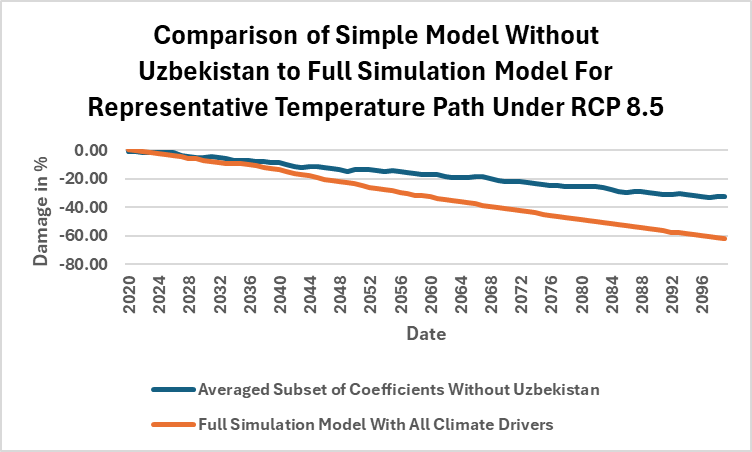
A competent academic reviewer should have been able to verify the data error very quickly. My econometric results would have taken a bit longer to confirm, but it’s very doable.
The Seven Deadly Sins of Econometrics
I’ll leave it to technically-minded readers to debate what the other six deadly sins of econometrics are, but there can be no doubt that the most mortal deadly sin of econometrics, the sin that lands you in the first circle of econometrics Hell, is the sin of data mining. When you data mine, you search for a specification of a model, such as a regression model, that yields a pre-determined conclusion.
Coincidentally (or perhaps not!), on the very day that Nature revealed the data error, the authors of the damage paper posted a revised paper in which they corrected the data error but then changed their model so that they got back their original very large economic damage numbers. They merely added a new term to the regression model and “presto,” all is well. Now they would just need to get the new version peer reviewed.
Piling On
About a week later, Nature posted a second critical analysis of the Nature paper model by Christof Schotz, also at the Potsdam Institute. Schotz, who is an expert in climate econometrics, came to very similar conclusions to my own on the AIC/BIC test as well as on the clustering issue, although he made different arguments. The authors of the damage paper ignored Schotz’s points (and mine) in their revision.
At this point, we have a giant data error, demonstration of invalid econometrics by me and by Schotz, a data mined revised paper with the original large economic damage results restored, and the authors vowing to get the new version of their data mined paper peer reviewed and re-published. Isn’t there now a very strong case to retract the paper with extreme prejudice? Well, Nature didn’t retract it. You probably continue to be surprised that that’s not how the academic review process actually works. More deliberation by Nature would apparently be necessary.
The Boomerang Retraction
In fact, four more months of deliberation were necessary, but finally the white smoke wafted from Nature’s headquarters in mid-December: the paper was retracted, sort of. Why did it take so long? My guess is they wanted to avoid the embarrassment of retracting such a highly influential paper, but they knew they had to do something, at least temporarily. It appears they used that time to invent a new retraction category in academic publishing: the boomerang retraction. Yes, the damage paper change was just over the line of a correction, so technically it had to be retracted, but don’t worry, it’s coming right back once it goes through academic peer review.
In the retraction notice, the phrase “controlled … for higher order terms as present in the Uzbekistan data” suggests the fix is already in.

The “higher order term” is what the authors changed in the regression model to restore their original large economic damage estimates. Apparently, when they corrected the Uzbekistan data and their damage numbers plummeted, the damage model authors suddenly realized they needed to add a higher order term to the regression model for some sort of correction. But oddly, the authors didn’t need the higher order term when they were unaware of the errors in the Uzbekistan data. Why not? Well, I put the higher order term in their original model with the bad data to see why: the economic damage in the original model would have been much too large—90% instead of 60% by 2100—to be credible when the higher order term is combined with the data error.
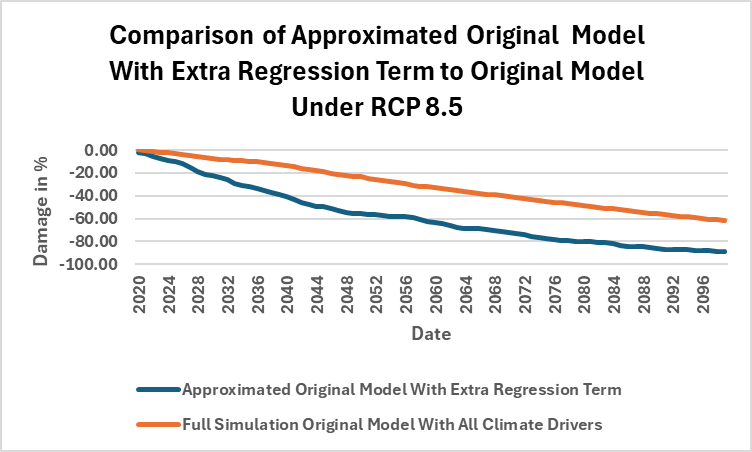
This data mining couldn’t be more brazen. Solomon Hsiang commented on the shenanigans in the change in the Nature damage model in the Washington Post, saying “Science doesn’t work by changing the setup of an experiment to get the answer you want. This approach is antithetical to the scientific method.”
Clearly, the Nature editors are ok with the data mining, since they’ve preannounced on their boomerang retraction notice that they’re amenable to a new peer review process. As editors, they could have dismissed the revised paper out of hand, but they didn’t. The unknown question is whether they will be able to find enough academic referees willing to go along with the charade.
What Should Judges Take Away?
The lesson that judges should take away is that the academic review process generally works well, but there can be strong incentives to oppose corrections when results turn out to be wrong. There’s a lot of academic integrity out there. In the damage paper case, Hsiang, his co-authors, and Schotz should be commended for standing up and challenging errors, especially when there can be real costs to doing so in the academic community. King should be congratulated for his academic integrity as well. Scientists and academics want to get to the right results and want to make sure that what is published is actually true. But there are also powerful incentives to oppose corrections.
We have to remember that the academic review process is limited: it’s just a challenge process, controlled by the journal editors who steer it. Also, careers and compensation depend on academic publication. When you add in the fact that many economic results, whether climate-related or not, have enormous policy implications, there’s always some politics and, unfortunately, potential shenanigans that can go on. When results that bring fame and policy relevance to authors and journals are shown to have been invalid all along, it’s not surprising that the authors and journals will fight hard to avoid embarrassment.
Academic journals are generally opaque and unaccountable. Most of the time, we have no idea what issues the peer review process actually covered. We also don’t know if an academic journal has received critical analysis of published papers unless the journal chooses to tell us. For all we know, the damage paper may have received other critical analyses but either the authors and/or Nature didn’t respond, or Nature rejected the submissions. The only reason you know of my involvement is because I’m telling you about it here.
So, based on what can and does go wrong in climate econometrics but also in general economically-oriented climate research, my suggestions to judges to help ensure that blatantly incorrect results are not introduced into evidence would be:
Require academic journals to disclose all referee comments for any paper that may be used in a court room
Require academic journals and paper authors to disclose all comments they’ve received even if they didn’t reply to them or they rejected them
Require authors to have created a replication package if their results are to be used. Nature has a strong policy in this regard. All authors must create a replication package as a condition of publication. Many journals have no such requirement.
Recognize the difference between academic peer review and replication and model validation. Models need to be replicated and validated before being used in the courtroom. The analysis I presented in this note is an example of the sort of model validation that could be done.
Recognize that when published papers have errors, there can be very strong forces opposing correction
An excellent piece. However, I am not in the least surprised at the failures of the academic review process. That has been a problem in climate studies for decades, as in other areas, notably nutrition.