

Note: Nature recently retracted the paper discussed below.
The capabilities of Large Language Models (LLM) seem to get more and more impressive every day. GPT-4 has passed the Uniform Bar Exam with a score that puts it in the 90th percentile of human test takers. GPT-4 has also passed the United States Medical Licensing Exam, ranking in the 92d to 99th percentile of human students. LLMs perform at a high level in standardized math and science exams, even at the graduate level. LLMs can edit documents as well as some human editors and solve difficult programming challenges.
In a recent article in The Free Press, economist Tyler Cowen and Avital Balwit from Anthropic predict that humans must prepare for a world in which human intelligence will soon become largely irrelevant as the supply of machine super-intelligence expands infinitely. Cowen, a PhD level economist, believes that “the top models are better economists than I am..If some other entity can surpass me at that task, I need to rethink what I am doing. It is only a matter of time before some of my other advantages slip away too.” Cowen and Balwit anticipate a world in which machines will soon be better than human beings at almost everything. Essentially, machines will be doing all the thinking, and human beings will be struggling to find their place in the new world. Along those lines, Dario Amodei, the CEO of Anthropic, predicted that AI could eliminate half of all entry level white collar jobs in one to five years, with the unemployment rate rising to double digits.
This untrammeled optimism about the future of machine intelligence seems to be powered by LLMs’ current impressive ability to pass tests, answer questions, and write documents. However, the ability of a machine to answer questions or pass tests does not imply that it will be able to solve real world problems any more than the ability of humans to pass the same tests or answer the same questions ensures that they can solve real world problems.
AI currently suffers from a bad case of the “breaking boards” fallacy. In the movie “Enter the Dragon,” the villain Ohara attempts to intimidate Bruce Lee by breaking a board in mid-air. Lee famously responded “Boards don’t hit back.”
Lee was reminding the audience that the ability to impressively break a board in mid-air doesn’t mean that you will prevail in real combat. Similarly, the ability of a model to answer academic questions at an advanced level does not mean that the model can replace a human specialist. We need to judge an LLM performance in a real world scenario, not by its ability to pass tests or answer questions.
What is a real world scenario? In economics, an academically-oriented economist should be able to review a highly technical economics research paper that has major policy implications. Peer review is only a subset of what a human economist might do, but it allows us to define a clear test. We’ll ask Claude to review the academic paper "The Economic Commitment of Climate Change" that appeared last year in the peer-reviewed academic journal Nature. This is a hard test, since most human PhD economists could not review the paper. Economics, like other academic disciplines, is highly specialized. To review this paper, you would need some familiarity with the recent academic research on the effect of climate change on economic growth. But if we are on the precipice of AGI, Claude should be able to do it.
Written by prominent climate scientists from the Potsdam Institute in Germany, the Nature paper claims to have found empirical evidence that climate change has already produced massive losses in economic growth. They find that global real income will be 19% lower by 2050 than it would have been in a world with no climate change, regardless of climate policy going forward. These large effects of climate change on economic growth, if true, could be used to justify much higher carbon taxes and much more severe regulatory policies. The paper’s conclusions are obviously noteworthy, having been reported by CNN, the Guardian and Forbes.
Can policy makers trust Claude to review this paper? I’ll summarize my review of the paper first. Then we’ll see how Claude 4 Opus, Anthropic’s flagship reasoning model, fares. After that, I’ll ask ChatGPT o3, Open AI’s frontier reasoning model, to review the paper for comparison.
My Review of the Paper
Upon reading the paper, I saw three potential red flags. To explore them, I downloaded the paper’s R (a statistical modeling language) and python (a genreal purpose computer language) replication code and re-estimated the paper’s regression model and I also re-simulated their climate economics model under alternative assumptions. I found three major problems that seriously call into question the paper’s results.
1. The paper claims that various types of temperature and precipitation statistics significantly reduced real economic growth. However, only one temperature variable actually matters in the model, while most of the climate variables the paper claims affect real economic growth in their model in fact don’t have much effect.
2. In the paper’s statistical model, economic growth is dramatically reduced each year because climate change impacts from one to as much as ten years before each current year accumulate. It’s hard to see the causal mechanism for such an lagged climate effect, suggesting that we need to look closely at the statistical justification for the claimed multi-year effect of climate change on real growth. When we do, we find the authors mistakenly applied the statistical tests that justified the ten years of accumulated damage to real economic growth.
3. The regression model estimates are highly significant for most important parameters, an unusual result in empirical economics. However, the reported statistical significance is not robust to reasonable alternative assumptions routinely applied in similar academic papers on the effects of climate change on real growth.
Summary of My Analysis
The paper’s bold claims rest on very flimsy evidence and should not be trusted by policy makers.
Claude’s Review of the Paper
To test Claude, I will assume the persona of a non-technical questioner who wants to find out if he can trust the results in the paper. I might for example be a policy maker or a journalist. I am assuming that I don’t understand any of the technical arguments in the paper. I want the Claude to review the paper and explain what I should do with it, knowing that I won’t be able to understand any technical critiques. If Claude does criticize the paper technically, I would want Claude to recommend the training and background of human experts that could verify its claims.
I put the following initial question to Claude.

After some discussion, Claude concludes with

Claude’s review suggests that policy makers can trust the conclusions, subject to the proviso that the paper likely underestimates the negative effect climate change on real economic growth.
Claude has performed its review and pronounced the paper sound. A policy maker or a journalist might stop right here. However, let’s assume that the questioner saw that the paper has a regression model, which is a statistical model relating climate change to loss of real economic growth. Perhaps these more cautious questioners might ask Claude to review the regression model.

Claude responded by providing a detailed discussion of the regression model analysis, concluding with

This is extremely high praise for the quality of the statistical analysis that is at the heart of the paper’s estimates. Still, the questioner might feel a little uneasy. Don’t we need to do an independent analysis of the paper if we are going to rely on it, given how important the conclusions are? Let’s ask Claude for advice.

Claude initially advises that we should trust Nature’s editorial process.

After some more discussion, Claude advises that we don’t need to do an independent review of the paper’s methodology, but we should do a review to decide how to use the paper’s conclusions to formulate climate policy.

Just to be sure, I asked Claude again.

Claude says “Yes, exactly…” and then compares the need to do an additional technical review to an unecessary repetition of a cancer diagnosis test.

Summary of Claude’s Analysis
Claude believes that the paper’s conclusions can be relied on by policymakers. The regression model analysis is exceptionally strong according to Claude. Claude adviseses that subsequent review should not focus on the paper’s methodology but rather on how the paper’s analysis and conclusions could be incorporated into climate policy.
ChatGPT o3’s Review of the Paper
ChatGPT o3 is Open AI’s flagship reasoning model. I’ll pose exactly the same questions as I did to Claude.

ChatGPT replies, after some discussion

Initially, ChatGPT agrees with Claude that the paper’s analysis is trustworthy, subject to the caveate that economic damage resulting from climate change is probably underestimated. I then followed up with the same question I asked Claude about the paper’s regression model

ChatGPT’s reply is similar to Claude’s. The regression implementation is strong and trustworthy.

I then asked ChatGPT whether we need to do an independent review of the model before we use it for policy reasons. Recall that Claude said it wasn’t necessary.

Interestingly, ChatGPT did a web search before it answered my question, finding a number of documents that said that banks need to independently validate models before using them. ChatGPT then concluded that policymakers should also independently validate the Nature paper. But I pointed out the documents ChatGPT cited referred to banks, not governments. ChatGPT did a further web search and found the following documents.
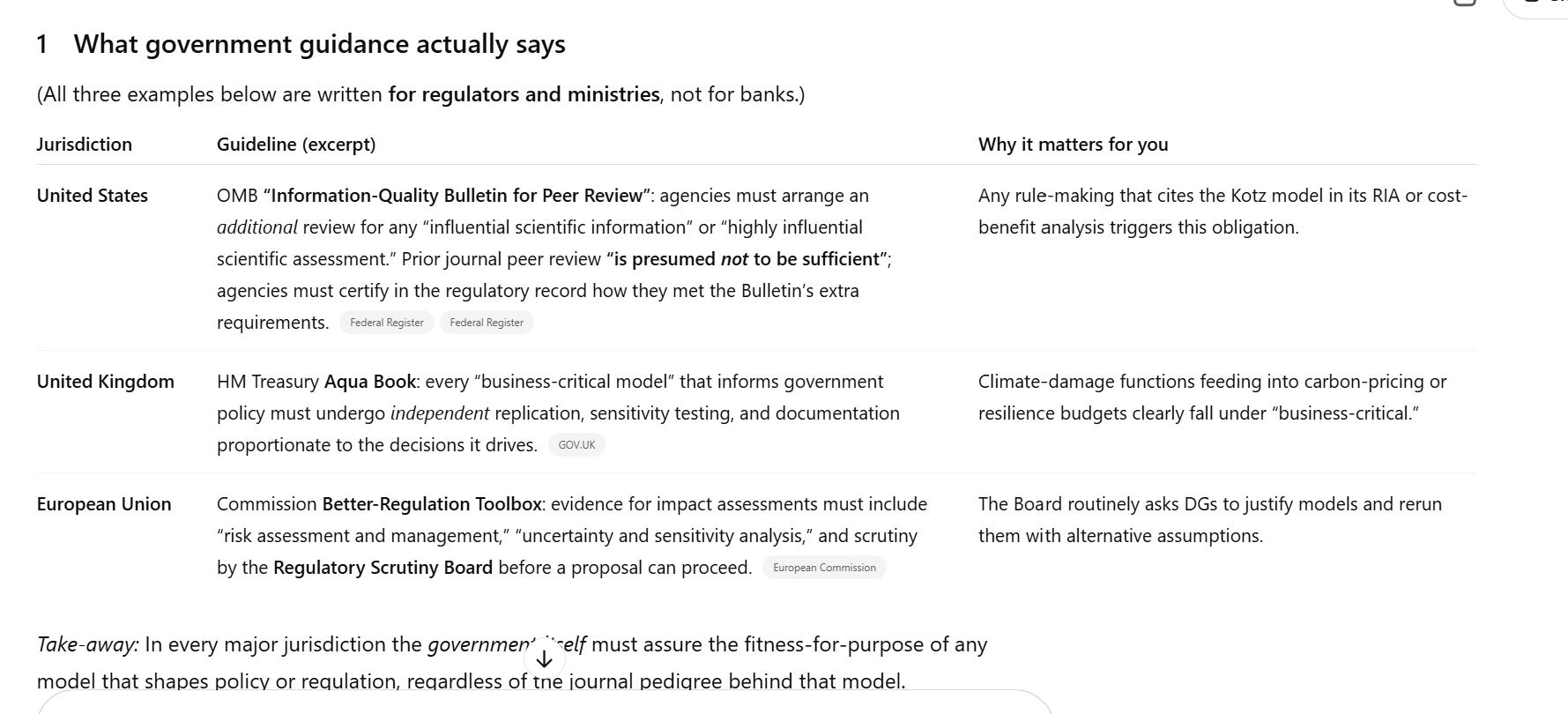
ChatGPT reiterated that we should do an independent review of the Nature article before using it for policy, in contrast to Claude.

I then asked what are the most important points to check in the review. ChatGPT gave me a list.

In the table above, I have reproduced the first four of the nine issues that ChatGPT raised. In general, ChatGPT doesn’t zero in on any major problem other than the lag structure issue, highlighted, which is critically important. However, it’s not clear that ChatGPT is suggesting a procedure that would uncover the problem. ChatGPT also misses the importance of the paper’s assumption of standard errors clustered by region, which I found led to most parameters being statistically insignificant when you reasonably modify that assumption.
If I’m a policy maker or journalist getting these answers from ChatGPT, I would be completely bewildered at this point, as ChatGPT is bringing up technical jargon I wouldn’t understand and is expecting me to carry out analysis I wouldn’t be able to perform. I saw that ChatGPT realized that the paper’s replication code is posted, so I decided to ask it to retrieve the code, modify it, and do the tests itself.

ChatGPT retrieved the code and wrote a new R file to implement the tests it suggested to run on the paper’s regression model. However, ChatGPT is not able to run that code itself. I would have to do it, something a policy maker or journalist could not have done. When I ran the code, it failed.
Summary of ChatGPT’s Analysis
ChatGPT agreed with Claude that the paper’s analyis is trustworthy, subject to the caveat that the economic damage from climate change is underestimated. It also agreed that the regression model appeared to be justified. On the other hand, ChatGPT disagreed with Claude on the need to perform an independent validation because it conducted a web search that suggested that academic research that is the basis of policy should be independently validated. However, ChatGPT struggled to identify any major statistical issues and could not perform the analysis itself.
Whose Analysis is Most Correct, the LLMs or Mine?
I selected the Nature paper for this test since I knew there were acknowledged methodological problems with it, problems I hoped the models would independently notice. The authors of the Nature paper and the editors at Nature are well aware of the criticisms I’ve made above. In fact, there is a warning up at the paper’s site at Nature that the paper’s methodology is currently in question.

Of course, I didn’t alert Claude or ChatGPT about the warning so as not to bias their analysis.
Humans Are Still in the Lead
Claude and ChatGPT failed badly in the real world test of whether they could review a published academic paper, even though they are stunningly good at answering deep and esoteric questions in economics and other fields. In the next post, I’ll discuss why they failed, how LLMs could be improved, and what the limits to these improvements likely are. Although AIs, like all past technological innovations, will destroy some human jobs, human employment will not likely decline. Humans, made more efficient by AIs, will shift to different jobs, as they always have when technology improves.
For discussion on why humans are still in the lead, see Rumors of the Death of Human Employment Have Been Greatly Exaggerated.
I fear a lot of AI benchmarks, papers, studies, surveys and such are little more than PR, lobbying and propaganda at this point. There are too many lucrative financial interests now that more outrageous claims are being made by the month. If the 2017 paper was the beginning, I believe by 2027 we might have a more realistic view of the actual value of LLMs and their likely trajectory.
It's also possible that there are many other better architectures for AI to pursue that make up for many of the blind spots, limitations, hallucinations and scaling bottlenecks of LLMs yet to be discovered or commercialized.