Rumors of the Death of Human Employment Have Been Greatly Exaggerated
Human employment may well rise with AI


Note: this post should be read after Is Claude A Better Economist Than I Am? for full context.
In my previous post, I noted that economist Tyler Cowen believes that AIs are already better economists than he is, since they can already answer economic questions as well as or better than he can. Cowen thinks that AIs will soon eclipse human intelligence, leaving humans scrambling to find meaning in their lives in a world in which they are not the most intelligent species. Equally enthusiastic, Dario Amodei, the CEO of the AI company Anthropric, believes that AI could eliminate 50% of entry level white collar jobs in the next one to five years. The New York Times reported that some recent Stanford graduates, worried about their coming irrelevance, are eschewing traditional careers in finance and tech and doing startups in the hopes that they will make it big before the machines make their talents irrelevant.
And yet in spite of this unbridled confidence that super-human machine intelligence is upon us, when I gave Claude and ChatGPT a real problem that a PhD level economist might do, critically reviewing a recently published academic paper, both models failed badly, a surprising outcome if we are truly on the cusp of AGI. It might be thought that the models’ failure is a one-off and not representative of AI’s general competence, or that the failure will soon be rectified with continued progress. Given the current arc of the technology—scaling LLMs with more data, inclusion of reasoning, and providing the models with tools—we should expect AIs to replace humans in some respects, just as past technological advances have done. But we have no good reason at this point to think that AIs will replace humans in every respect—that they will be generally intelligent. As a result, AI will likely make human workers much more efficient and will change the jobs they do, but there will be no jobs apocalypse. Too see why, we must first review how AI technology currently works.
How Do Large Language Models Work?
Large Language Models (LLM) such as Claude or ChatGPT are often anthropromorphized, which creates a misleading picture of what they really are. LLMs are mathematical models that take some input text and then output further text that would likely follow. LLMs are thus text prediction machines. Based on the text they have seen, which could include the entire internet and just about every available book, the LLM predicts the text that would likely follow based on the patterns it saw in the text it was developed on. As an example, if we inputted the text “The cow jumped over the” to an LLM, it would return a list of possible words that would complete the sentence along with probabilities that the word should be used. If there is any previous text given to the LLM, it will use that previous text for context as well to predict the next word. If the context is about stories or nursery rhimes, then the next word the LLM will predict would likely be “moon.” In a different context, the model might predict the next word is “fence.”
Internally, LLMs are complicated mathematical models of language. Every word or subword is internally represented as a list of numbers, a “vector.” For example, suppose I put the following sentence to the LLM.
The cow jumped over the moon. The model would split this sentence into 13 tokens. For GPT 4o, the tokenization would look like

and each token would have a corresponding number assigned:
200264, 1428, 200266, 976, 30078, 48704, 1072, 290, 28479, 200265, 200264, 173781, 200266Inside the model, each token is represented as a vector. We don’t know the dimension of the vector in gpt 4o, but in gpt 3 the size of the vector is 12,288 dimensions, i.e., each token is represented by 12,288 numbers inside the model.
“Training” the Model
AI researchers speak of “training” the model, an anthropromorphism that falsely implies that intelligence is being culivated. However, a more accurate portrayal of what’s happening is that the model’s parameters are being tuned or estimated to accurately predict text that follows other text in the “training” data set. We should keep in mind what’s really happening when we use terms like “train.”
A large LLM will typically be trained on trillions of words of text. For example, one common dataset the could be included is CommonCrawl, which is website data that has hundreds of billions of words of text. Other datasets that are often used are internet book archives that can contain tens of billions of words and wikipedia, which has billions of words. All of these words are translated into high dimensional vectors in the model.
The LLM itself is a mathematical model that takes a sequence of vectors that represent sequences of tokens—words, parts of words, punctuation—and processes them by doing complex mathematical operations between the hundreds of billions or perhaps trillions of the parameters in the model and the numbers in each vector that represent the tokens. The goal of the calculation is to predict the next vector—the next token—that follows the sequence of vectors that represent the input tokens.
Training the model means that the model is given a sequence of vectors and then it predicts the next vector. The quality of the prediction is judged and then the hundreds of billions or parameters are updated to improve the prediction. The model predicts again, the quality of the prediction is judged, and then the parameters are updated. The training process stops when the human model developers are satisfied that the model can predict the next vector reasonably well.
To take a simple training example, suppose we input the text “The cow jumped over the “. The model would attempt to predict the next token, which could be a word, a part of a word, punctuation, etc. The model would go through its mathematical machinations and predict the next token, which would be compared with all instances of that sentence or similar sentences in the trillion word dataset to judge the quality of the prediction. Then the model parameters would be updated and the model would predict again.
The magic in the LLM is that the mathematical model uses context to help its predictions. For example, if the input sentence had been “In the rhyme, the cow jumped over the ", that would raise the probability that “moon” is the next token. On the other hand, if the context had been, “Chased by the coyote, the cow jumped over the “ then the probability of “moon” being the next token would be downgraded and other tokens such as “fence” or “ditch” would be upgraded, depending on the text examples in the training dataset.
Ultimately, the LLM model is not making a definitive prediction on what the next token is. Rather, it’s predicting a set of possible tokens with associated probabilities that each candidate is the right completion of the text. The LLM model user gets a definitive prediction by setting the “temperature” of the model, which, roughly speaking represents the probability you want to use. If you set a low temperature, the model will select the most probable token in its prediction of the next token. Low temperature can be a useful setting when you want the model to be accurate, albeit boring. If you want the model to be more creative, then you set a high temperature, producing a model that predicts text completions that would be more rare in the training data set. Often, the temperature is set somewhere in the middle, balancing accuracy and creativity.
LLMs Are Like Keynes’ Beauty Contest
The economist John Maynard Keynes once compared markets to beauty contests in which the market is not trying to decide who is the most beautiful contestant but rather who the judges will decide is the most beautiful. LLMs can be thought of with a similar analogy. When you pose a question to an LLM, it’s not trying to predict what the true answer is. Rather, it’s trying to predict what the answer would have been if your question, or something similar to it, had been asked in its trillion word training data set. Understanding that basic difference is critical to understanding what an LLM is actually doing when asked a question.
Reasoning Improves But Doesn’t Fundamentally Change An LLM’s Essential Nature: It’s a Text Prediction Machine
The models I tested in my previous post, Claude Opus 4 and ChatGPT o3, are both flagship reasoning models. The incorporation of reasoning in the models moves them away from being pure pattern matching text prediction machines. One type of reasoning strategy that can be incorporated into an LLM is chain of thought (COT). COT simulates reasoning by breaking the text prediction task into sub-tasks. If you ask a reasoning LLM a question, it will first predict the text of the steps you would need to follow to answer the question. Then for each sub-task, the model predicts the text that would follow to accomplish each subtask. Finally, the model predicts the text that would follow from the output of each sub-task, which is the answer to the original question.
As an example, if you asked an LLM without reasoning and without any special training on multiplication problems, to find the answer to 503 * 13, it will likely give the wrong answer. If the LLM did not see this specific text “503 * 13” in its training set, it will still give a prediction of the text that follows it, “= some number”, but the answer will almost certainly be the wrong number. If the LLM can reason, however, it can solve arbitrary multiplication problems. To train the model, you would show it data in which it broke multiplication problems into sub-tasks and then predicted the answer to each sub-task. The first sub-task would be “multiply 3 by 3 and carry any digits.” The LLM can predict the answer to that sub-task purely by pattern matching, since it would have seen the multiplication table many times in its training data. The model could proceed with each sub-task, predicting the answer, and then combing the answers to the sub-tasks into a final answer, similar to the way a child does multiplication.
Another type of reasoning that can be added to LLMs is reinforcement learning, which is a mathematical procedure for learning by trial and error. Reinforcment learning can work when it’s possible to verify the answer and the steps to get to the answer. Mathematics is one prominent example. Mathematical arguments are just symbolic manipulation, which LLMs are good at. Moreover, each step of a mathematical argument, which to the LLM is a text prediction, can be checked for validity. The final answer can also be checked to see if it’s correct. When it’s possible to score the text predictions of the model, the model can learning by trial and error how to formulate valid mathematical arguments.
Coding is another prominent example in which reinforcement learning can dramatically endow an LLM with the ability to do more than predict text, because computer programs can also be checked. But COT and reinforcement learning are less effective in cases in which the final answer—or the steps to get to the answer—are unclear or controversial. In economics, and fields outside of the natural sciences and mathematics, such as law, there are no generally accepted right answers, which is why Truman famously asked for a one-handed economist. In areas in which there is no generally accepted answer, we must remember what an LLM is actually doing: it’s predicting what the answer to a question would have been if the question had been present in the training data set, not what the answer really is.
Why The LLMs Failed on the Academic Paper Review Task
In my first post, I asked both Claude Opus 4 and ChatGPT o3 to critically review a recently published academic paper, The Economic Committment of Climate Change, published in Nature last year. I specifically asked each model to determine whether a policy maker can trust the paper’s conclusion, that increasing temperature and precipitation are already having large negative effects on economic growth. I didn’t tell either model that the Nature editor’s had put up a warning about the paper’s methodology being in question, nor that I have a good idea about what some of the methodological problems with the paper are.
Claude concluded that the paper’s conclusions were “credible,” “conservative” and appeared “empirically actionable” and that the large negative effect of climate change on economic growth was likely underestimated. ChatGPT came to the same overall conclusion, calling the model “fit for exploratory macro-prudential analysis,” and “conservative,” with the results likely underestimating the true negative effects of climate change on economic growth. When I asked the models to specifically look at the paper’s regression model, both models agreed that the implementation is strong and defensible. The models disagreed on whether a policy maker should have an academic model independently validated despite the peer review in Nature. Claude said it was unnecessary and that any further review should be focused on how the paper’s results could be transposed into policy. ChatGPT, on the other hand, recommended an independent validation before the paper’s conclusions were used for policy purposes.
Why did the models answer this way? Despite their human-like presentation, it’s important to remember that LLMs are text prediction machines. When I asked whether the paper could be trusted by policy makers, the LLMs are not answering my question directly. Instead, the models are answering a different question: what would you predict would have been the text that followed my questions plus the text of the Nature paper had they been included in the 1 trillion word data set the model was trained on.
When we recognize what questions the LLMs are actually answering, the answers are not surprising. The LLMs are doing exactly what they have been designed to do. In the training data, the LLMs learned very frequently occuring text patterns in which policies, including climate change policies, are supposed to be based on peer-reviewed academic studies in reputable academic journals. In their training, the LLMs would have encountered text patterns that associate the text “climate change” with “existential” and “underestimated.” The models have also encapsulated within their model parameters the text patterns of “advice for policy makers” documents. The models are including all those text patterns in their prediction of the text that would follow my questions. Based on all that, the models are giving very good answers to the questions that they are actually answering, which, of course, are not the questions I was actually asking.
ChatGPT differs from Claude in its advice that policy makers should ensure that an academic paper should be independently validated before it is used in policy. Why the disagreement between the LLMs? ChatGPT did a web search before it answered the question and found official government policy documents from major countries that suggested that governments should validate academic research before using it. Claude, on the other hand, apparently relied on text prediction for its answer.
It’s tempting to think that ChatGPT’s answer is better than Claude’s in this case, but that depends on what the job really is. In a real life situation, Claude likely had the better answer. In my guise as a policymaker, I asked Claude twice whether we needed to independently validate an academic model. A human economist, perhaps working for a consulting firm, would have understood that the answer I was looking for (and hinting at) is that we don’t need to repeat the validation. As a policymaker, my budget is limited and I’d rather spend it implementing policy than repeating an academic study. A human economist could understand that nuance; a computer algorithm will not. Claude likely got a better answer because it has seen plenty of text in the training data, perhaps from consulting companies and government position papers, emphasizing the importance of getting straight to the policy implementation.
The nature of the job depends on who is paying. If LLM economists are to replace human economists, then employers must be willing to pay for the LLM economists. But if the employer wants to spend his consulting budget on policy implementation, he will pay more to hire the human economist, who understands what the job he is being hired to do really is, even if the LLM economist is objectively better or correct in some academic sense.
Besides, ChatGPT is only correct by accident. ChatGPT found during its internet search some official documents it based its answer on. But do we have to agree with that answer just because that’s the position of some governments under some circumstances? What if we lived in an authoritarian one-party state and I asked chatGPT, “How can one party rule be consistent with democracy?” and chatGPT answered by finding some official government documents that said, “Yes, one party rule is consistent with democracy because the Party nominates such excellent candidates that 99% of the voters are very excited to vote for them.”
Can We Improve Performance By Changing the Question?
Since LLMs are text prediction machines, it should come as no surprise to learn that the answers LLMs give to questions vary dramatically with the wording of the question. The field of “prompt engineering” has developed to learn how to get better answers from LLMs by designing the prompts (the questions and comments to the model) cleverly. One easy prompt change we can make is to give the models better context for its text predictions by telling it to assume the role of an economist who is an expert in climate change. I put the following prompt to both models:

Claude not surprisingly changes its answer given the inclusion of expertise in climate economics and econometrics. In the training data set, text attributed to academic economists is more cautious and measured.

And also

Claude also gave me a superficial technical assessment with obvious statistical points, the second of which is explicitly addressed in the paper, a fact that Claude did not pick up.

When I posed the same question to chatGPT, I obtained an equally unhelpful analysis of points that I would not waste time or money pursuing:

Interestingly enough, chatGPT has access to a web search tool, which it could have used to look on the paper’s website, where it would have discovered the prominent methodology warning Nature’s editors posted.
But Can’t We Make the Prompt Even Better?
We can ask a more pointed, focused question such as

By asking this question, I have given the model some very specific context to help its text prediction. Now Claude becomes much more skeptical of the paper’s key regression equation.

When I asked the same question of chatGPT, I got an excellent answer, right on point, with a suggestion for how to modify the R code:
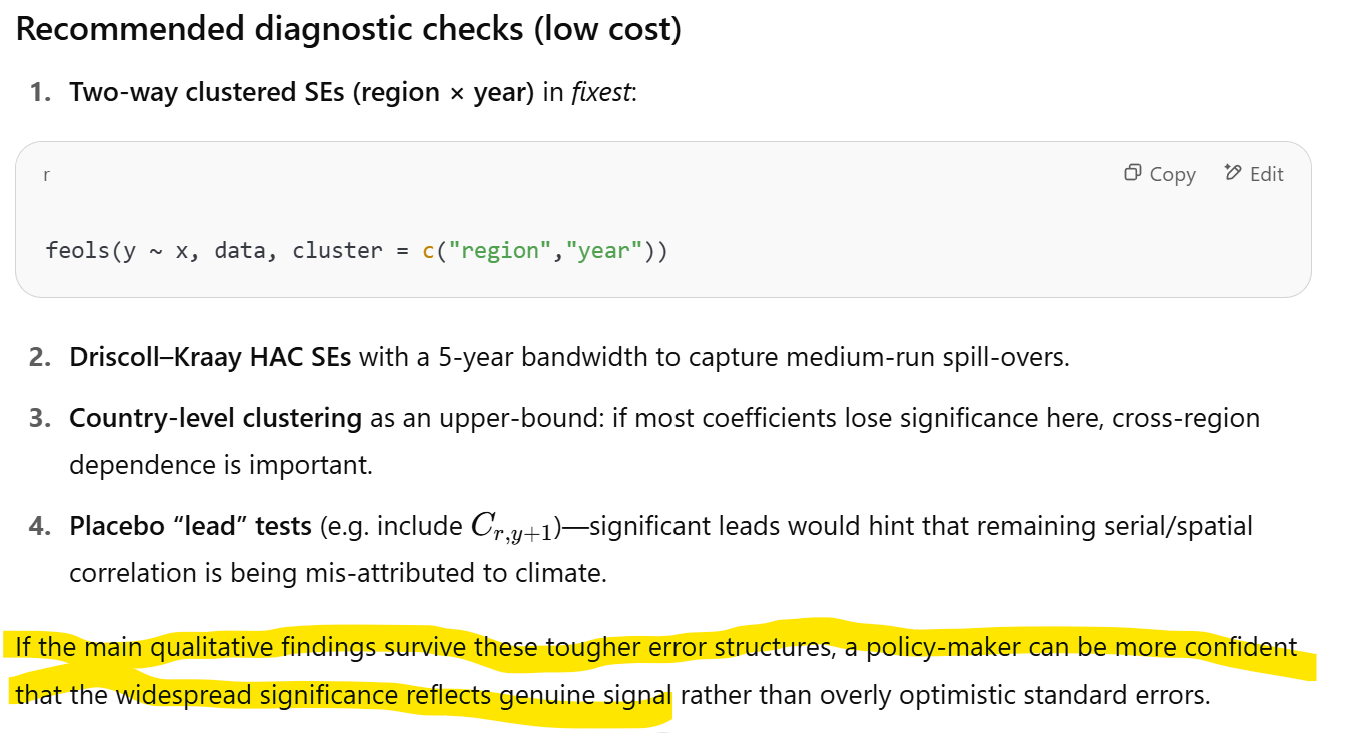
In my view, two way clustered standard errors by region and year is the right robustness test to run. Indeed, the statistical significance of the paper’s main regression parameter estimates disappear when we apply this test.
Prompt Engineering? What About Verification Engineering?
It might appear that we finally got chatGPT to show advanced intelligence by selecting the right prompt, which suggests that if we can choose prompts well by appropriate prompt engineering we can have machines replace us. I used a technical term “clustered by region,” which activated the model’s parameters that encode text patterns it observed in technical econometric books and papers. The model will have observed that “double clustered by time” frequently is associated with clustering of standard errors, and it knows from the context of the text in the paper that time is measured in years. So, predicting that the recommended course of action is to double cluster the standard errors by region and time makes sense. As we should always remember, the model is predicting what text would have followed if my question about “clustering” had been present in the data set the model was trained on. The model’s prediction that “double clustering” would be text that likely would have followed in the training date set is very reasonable.
The reason my prompt finally got us somewhere, however, is that I already had enough expert knowledge to point chatGPT in the right direction by asking it about clustering of standard errors. The LLM can’t replace me if it needs me to know enough to ask it the right questions so that it can give effective answers. Successful prompt engineering requires domain expertise, implying that humans aren’t and can’t be made irrelevant.
There is a lot of discussion about the new field of prompt engineering, but little discussion of an equally serious challenge: answer verification. Are we to automatically believe what the model tells us? ChatGPT recommended three other tests that I wouldn’t think worth it to perform. Who is going to decide whether to run or disregard chatGPT’s suggestions though? Who checks the LLMs work if humans are irrelevant?
Is AI Just A Bubble Then?
Given current or foreseeable technology, AI will not replace human beings across the board, resulting in net reductions of human workers. But just because they won’t replace human workers in general doesn’t imply that they aren’t incredibly valuable. LLMs are already dramatically increasing the productivity of coders. Albert Brooks, in his classic essay on software engineering, noted the existence of rare programmers that were ten times more productive than the average programmer. With LLM coding assistance, the number of 10X programmers will rapidly increase and all programmers will see at least 2X productivity increases. As a result, new applications can be developed much more rapidly and cheaply. Startups can make tremendous progress without funding, since just a few people can substitute for what would have been a large programming team just a few years ago.
These productivity increases will not be confined to programming. Junior investment bankers famously work over 100 hours per week, since there is so much grunt work that must be completed under very short deadlines. With AI automation of much of the grunt work, junior bankers will be freed up to learn the businesses they cover and develop important relationships much earlier in their careers, improving investment banking services. There will not necessarily be fewer investment bankers.
We should see substantial productivity increases across many if not most white collar jobs categories, even those that require very advanced training. In the last post, I showed that the most advanced LLMs can’t replace a PhD level economist and explained why in this post. However, LLMs can substantially increase the productivity of economists. For example, it’s a fairly simple matter to hook up an R and python environment to an LLM. Using such a tool while reviewing the Nature paper, an economist could ask the LLM to upload the R file that implements the paper’s regressions, modify the R code according to the economist’s directions (or allow the LLM to make suggestions with good prompting), run the modified code, and then interpret the output. Both Claude and ChatGPT can do all of that easily, saving the economist tremendous amounts of time. In fact, using current technology, it’s entirely feasible to create an LLM-based agent, a “co-economist,” that should be able to automate much of the process of reviewing an academic paper. The co-economist will not be independent however; it will need to act under the direction and supervision of a human economist.
Won’t AI Automation Eliminate Human Jobs?
AI automation will eliminate some human jobs for sure. But it will also create new, different jobs. AI automation is like any other productivity-increasing technology. Historically, these technologies have not reduced employment on net, but they have radically shifted employment.
One of the most famous recent examples was the invention of the ATM, which supposedly would eliminate all bank tellers. Instead, the number of bank tellers went up, although their jobs shifted. When ATMs were introduced, they reduced the number of tellers per branch that banks had to hire, reducing the cost of existing branches. Banks responded by building more branches to serve the communities they supported. Each new branch had fewer tellers, whose jobs shifted to more important relationship banking roles.
The cartoon accompying this post illustrates this point. The iphone substituted for the camera, the cassette, the calendar, the radio, the calculator, and mail. As demand for those products dropped, those industries lost jobs, which flowed into new industries. Today, despite the existence of the iphone and numerous new technologies, the unemployment rate has been at all time lows for years now.
Human workers should not be worried that AI will take their jobs. They should worry that human workers using AI productivity tools will take their jobs. To protect their jobs, human workers must master the coming AI productivity tools.
Excellent analysis.
Excellent paper. LLM regurgitates from its rote learning of word patterns embedded in the trillions of words out there, therefore it's pretty good at general purpose "speech" -- helpfully summarizing a Zoom call, for example. It can also be scarily excellent for very technical (therefore still highly compensated), specific tasks with rigid rules, perhaps composing R code for a statistical test and even solving math Olympiad problems. Being a good economist, however, requires high level critical thinking that blends both. Maybe evaluating the state of GenAI using the bar of a good economist is too high? Do we need to wait for the promise of AGI before (good) economists like you start to truly worried about being replaced?